By Omar Farouk KOUGBADA — Google Developer Expert in Flutter & Dart, CEO of KOF Corporation
Ask GPT-4 about Togolese tax law. Ask it about the 2024 national budget. Ask it who runs the Office Togolais des Recettes.
It will hallucinate, confidently, fluently, and wrongly.
This isn’t a criticism of these models. It’s a structural problem: Togo’s public data is scattered across dozens of government portals, written in French, and virtually absent from the training sets of every major LLM. The same is true for most of francophone West Africa.
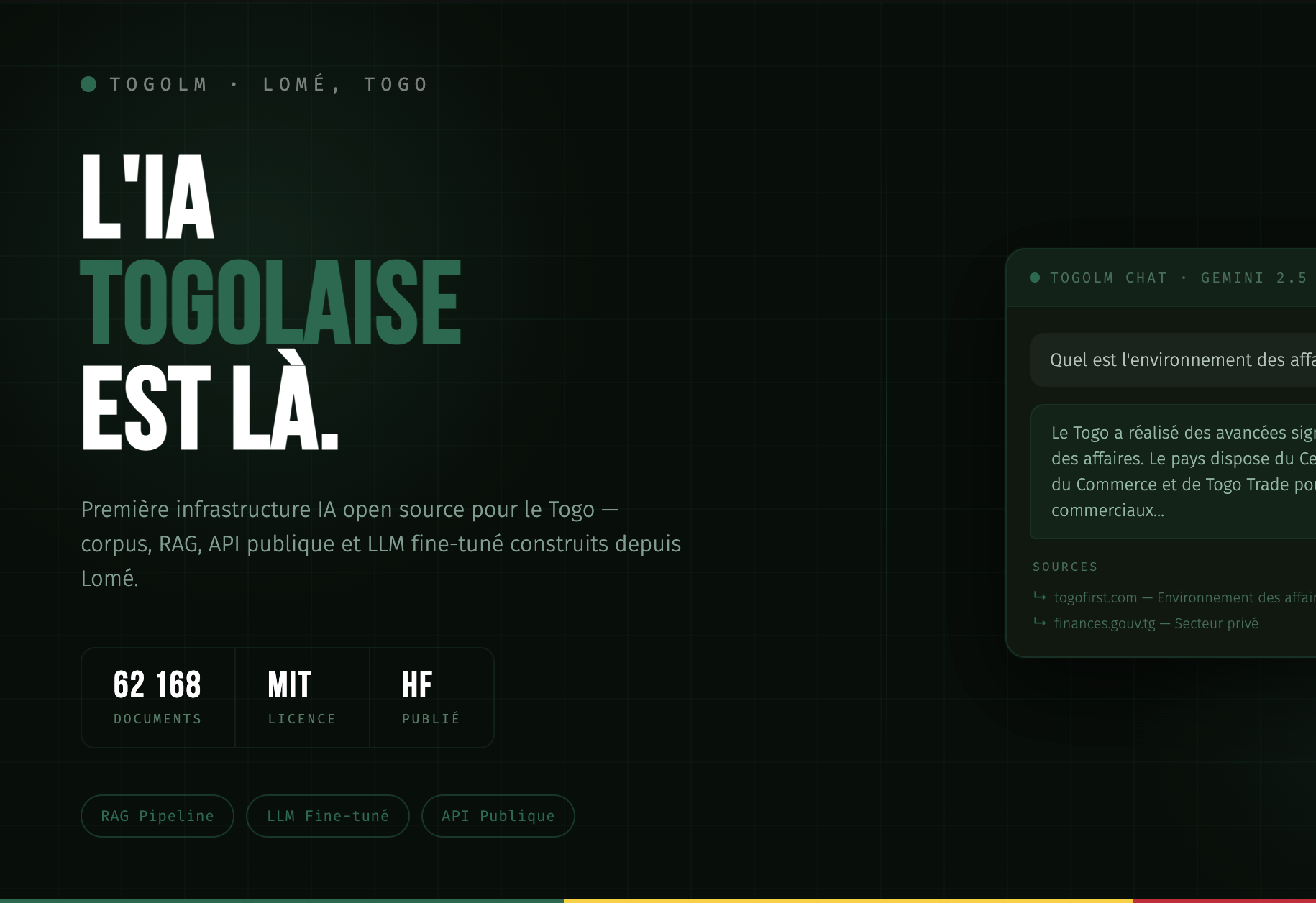
I built TogoLM to fix that.
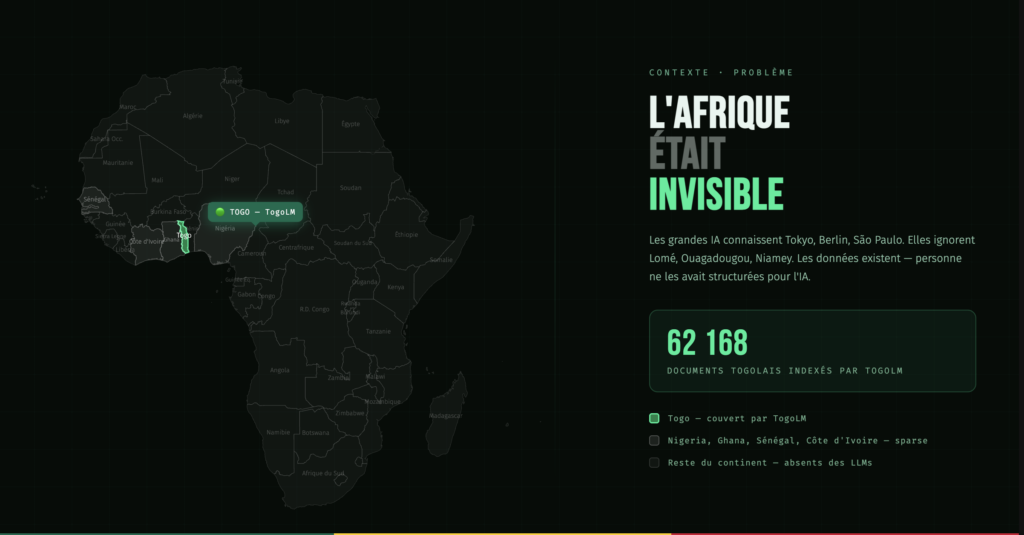
The Problem: Africa Is Invisible to LLMs
When I started integrating AI into production apps for Togolese clients : a recruitment platform, a USSD service for citizen support, a health reporting tool, I kept hitting the same wall.
The models knew nothing specific. Not the legal framework for creating a business in Togo. Not how the public procurement process works. Not the structure of the national education system. I was building AI-powered products on top of a knowledge base that didn’t include the country my users lived in.
The data exists. The Togolese government publishes laws, budgets, statistics, and administrative guides online. The problem is it’s unstructured, spread across 20+ portals, inconsistently formatted, and no one has ever assembled it into a usable corpus.
So I did.
What TogoLM Is

TogoLM is a complete open-source pipeline from raw web scraping to a fine-tuned LLM and public REST API that any developer, startup, or institution can build on.
It has four layers:
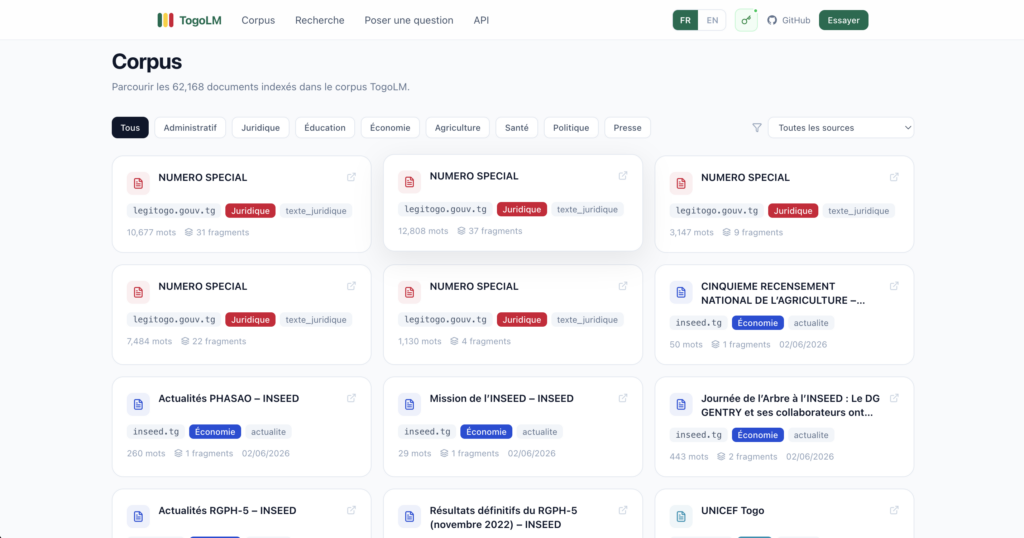
1. Corpus — 62,168 structured Togolese documents scraped from government portals, the national assembly, the tax authority, statistical agencies, and press sources. Every document is cleaned, chunked into 400-word segments, embedded, and stored in PostgreSQL with pgvector. The full corpus is published on Hugging Face: togolm/togolm-corpus-v1.
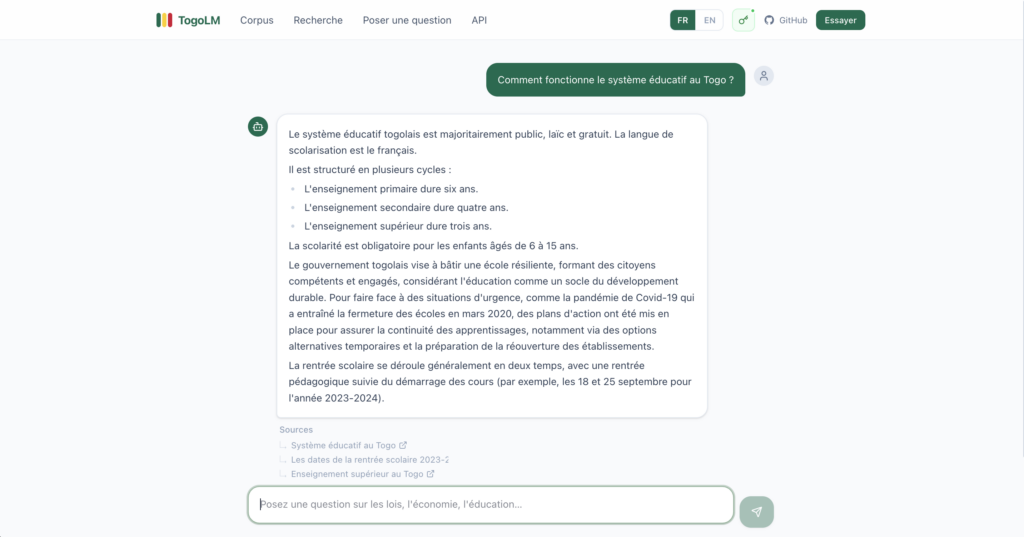
2. RAG Engine — Retrieval-Augmented Generation over the corpus. When you ask a question, the system retrieves the most semantically relevant chunks and passes them to Gemini for grounded generation. No hallucination about things Togo never said.
3. Public API — REST endpoints anyone can call: full-text search, document browsing, RAG queries with SSE streaming, and embedding generation. Built with FastAPI, fully documented, Docker-ready.
4. Fine-tuned LLM — Mistral 7B Instruct v0.3 adapted to the Togolese context using QLoRA. The first version is live on Hugging Face: togolm/togolm-7b-instruct-v1. The fine-tuning pipeline is fully open: dataset generation, Alpaca/ShareGPT formatting, SFTTrainer config, and a ready-to-run Google Colab notebook.
The Hardest Part: The Data Problem
I expected the technical challenges, building a RAG pipeline, setting up QLoRA fine-tuning, streaming LLM responses over SSE. Those were solvable with time and the right libraries.
What I didn’t fully anticipate was the data collection problem.
Togolese government websites are not built for scraping. Some are React SPAs with no sitemap. Some have SSL errors. Some simply go offline for weeks. The Journal Officiel, the official gazette where all laws are published, had documents scanned as images, not text. The national statistics agency (INSEED) serves data in PDFs with inconsistent formatting across years.
Building the corpus meant writing a custom Scrapy spider for each source, building a cleaning pipeline that handled HTML artifacts, encoding issues, and inconsistent French orthography, and manually curating categories across sources that used completely different taxonomies.
The result is 20+ active sources across legal, political, economic, health, and press categories with a clear roadmap for what’s still missing.
This is the kind of data engineering work that doesn’t show up in a tutorial but determines whether an AI system is actually useful.
Why Open Source
I could have kept this proprietary. A Togolese LLM API with no competitor would have been a viable SaaS.
But that misses the point.
The goal isn’t to own the data layer for Togo. The goal is to build it and make sure developers, researchers, and institutions across West Africa can use it, extend it, and replicate it for their own countries. Benin, Burkina Faso, Senegal, Côte d’Ivoire all have the same problem. TogoLM is a template as much as it is a product.
Africa doesn’t need to wait for OpenAI to decide it’s worth fine-tuning a model on. We can build the infrastructure ourselves.
The Stack
For those who want the technical details:
- Scraping: Scrapy with per-source spiders, JOBDIR-based resumable crawls
- Processing: HTML → clean text → 400-word chunks → embeddings (MiniLM local or Gemini API)
- Storage: PostgreSQL + pgvector, full-text search with
ts_rank+ ILIKE fallback - API: FastAPI, SSE streaming for RAG responses, 11 pytest integration tests
- Fine-tuning: QLoRA on Mistral 7B Instruct v0.3, SFTTrainer, dataset generated via Gemini Q&A pair generation
- Showcase: Next.js 16 + Tailwind v4, corpus browser, full-text search UI, streaming RAG chat
- DevOps: Docker Compose, GitHub Actions CI/CD
- Try by yourself here : https://togolm.kofcorporation.com/
All of it is MIT-licensed. The corpus is CC BY 4.0. The fine-tuned model will be Apache 2.0.
What’s Next
The first model togolm-7b-instruct-v1 is published on Hugging Face alongside the full corpus dataset. Both are available now.
Next steps: expanding the corpus to 100,000+ documents, adding health and labor ministry sources that are currently unreachable, and building a Flutter SDK so mobile developers in Togo can integrate TogoLM directly into their apps.
Try It / Contribute
The repository is live: github.com/omarfarouk228/togolm
If you want to contribute, new corpus sources, scrapers, API improvements, or translations, the CONTRIBUTING.md has everything you need.
And if you’re building AI products for underrepresented languages or regions, I’d love to hear from you.
Omar Farouk Kougbada is a Senior Full Stack & AI Engineer, Google Developer Expert in Flutter & Dart, and founder of KOF Corporation, a software engineering firm operating across Africa, France, and the UAE. He builds production AI systems and open-source tools for the African tech ecosystem.